
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 정렬
- machine learning
- C++
- instaloader
- SQL
- Regression
- programmers
- 스택
- python3
- GIT
- db
- 국민대
- 머신 러닝
- LSTM
- PANDAS
- Python
- 프로그래머스
- Heap
- 데이터베이스
- 회귀
- 국민대학교
- 파이썬
- gan
- Stack
- OS
- Seq2Seq
- 운영체제
- 재귀
- googleapiclient
- kmu
- Today
- Total
정리 노트
퀵 정렬(Quick Sort) (with Hoare) 본문
이 글은 제가 저번에 적은 글에 이어서 작성하는 글입니다. 그러니 이전 글을 읽고 이 글을 읽어주시기 바랍니다.
2022.10.22 - [개념 정리/알고리즘] - 퀵 정렬(Quick Sort) (with Lomuto)
두 번째 Partiton 방법
이번에 소개하는 partition 방법은 Hoare가 제시한 방법입니다.(사실 퀵 정렬 알고리즘을 제안한 사람이 Hoare입니다.) 이번 partition도 pivot 값을 배열의 가장 왼쪽 값으로 정하고 시작합니다.

i와 j의 초기값은 각각 -1, 배열의 길이로 배열의 양 끝을 지정하는 인덱스입니다. 먼저 i의 값을 하나 증가시키고 i번째 원소가 pivot값보다 작으면 다시 i값을 늘려줍니다. 이 과정을 배열의 i번째 값이 pivot보다 크거나 같을 때까지 반복합니다. 다음으로는 j를 하나 감소시키고 j번째 원소가 pivot보다 크거나 같으면 다시 j값을 줄입니다. 이 과정을 배열의 j번째 값이 pivot보다 작을 때까지 반복합니다.
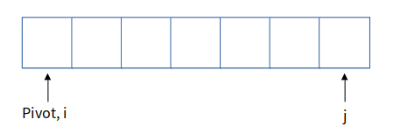
위의 사진 같은 상황이 되었다고 합시다. 지금처럼 i가 j보다 작은 경우 i번째 원소와 j번째 원소를 swap 합니다.
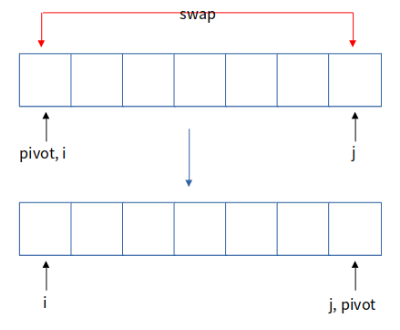
이 상황을 보면 Lomuto의 partition과 차이가 있음을 알 수 있습니다. Lomuto의 경우, pivot 값이 제 위치로 찾아갔습니다. 그러나 Hoare의 경우, pivot 값이 제 위치로 가지 않습니다! 이 과정을 i값이 j값보다 크거나 같아질 때까지 반복합니다. Hoare partition의 경우 pivot과 j번째의 원소와 swap하지 않고 이대로 partition을 종료합니다. 따라서 partition의 결과가 아래와 같이 될 수 있습니다.

j의 값을 pivot의 인덱스로 반환해줍니다. 이를 C++ 코드로 구현하면 아래와 같습니다.
int partition(int* numArr, int low, int high)
{
int pivotPos = -1;
int pivotValue = *(numArr + low);
int i = low - 1; int j = high + 1;
while (true)
{
while (*(numArr + ++i) < pivotValue);
while (*(numArr + --j) > pivotValue);
if (i < j)
{
int tmp = *(numArr + i);
*(numArr + i) = *(numArr + j);
*(numArr + j) = tmp;
}
else
{
pivotPos = j;
break;
}
}
return pivotPos;
}코드를 보면 while 문 안의 내부 반복문에서는 간단한 연산(증가, 감소)만 이루어지는 것을 볼 수 있습니다. 따라서 데이터의 이동이 있는 병합 정렬보다 퀵 정렬을 사용하는 사람들이 있습니다.
퀵 정렬 코드(C++)
partition 때 설정한 pivot이 제 위치에 가지 않았으므로 recursive 하게 들어갈 때 pivot값을 같이 가지고 가야 합니다. 이는 Lomuto 방식을 사용했을 때와 다른 점입니다. 따라서 이에 대한 코드는 아래와 같습니다.
void quickSort(int* numArr, int start, int end)
{
if (start < end)
{
int pivotPosition = partition(numArr, start, end);
quickSort(numArr, start, pivotPosition);
quickSort(numArr, pivotPosition + 1, end);
}
}이번에는 pivotPosition - 1이 아닌 pivotPosition을 넣었습니다.
(2022.10.23. 일요일 추가) Partiton 방법이 바뀌어도 여전히 In-place 알고리즘이면서 stable하지 않은 알고리즘입니다. 예를 들어 길이가 4인 정수 배열 {4, 4*, 2, 4**}을 정렬하면 {2, 4*,4, 4**}가 됩니다.
'개념 정리 > 알고리즘' 카테고리의 다른 글
| 백트래킹(Backtracking) (0) | 2022.11.13 |
|---|---|
| 동적 계획법(Dynamic Programming, DP) (0) | 2022.11.02 |
| 퀵 정렬(Quick Sort) (with Lomuto) (0) | 2022.10.22 |
| 병합 정렬 그 두 번째 이야기(Merge Sort) (0) | 2022.10.21 |
| 병합 정렬(Merge Sort) (0) | 2022.10.20 |



