
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- python3
- 국민대학교
- programmers
- SQL
- 머신 러닝
- db
- instaloader
- Python
- OS
- LSTM
- Seq2Seq
- 회귀
- gan
- 스택
- Regression
- kmu
- 프로그래머스
- 재귀
- 파이썬
- Stack
- 국민대
- 운영체제
- Heap
- GIT
- googleapiclient
- 정렬
- machine learning
- C++
- 데이터베이스
- PANDAS
- Today
- Total
정리 노트
확률적 경사 하강(SGD) 본문
이 포스트는 국민대학교 소프트웨어학부 '컴퓨터 비전' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 질문과 오류 지적은 매우 환영합니다!
Gradient Descent(경사 하강)
손실 함수를 MSE Loss(오차 제곱의 평균), f라고 하고, 변경해야 할 값을 w라고 할 때
$$ w = w - \alpha * \frac{\partial f} {\partial w} $$의 식을 통해서 고쳐 나갑니다.
MSE 손실 함수(아래 식에서의 'f')는 dataset의 모든 값들을 보고 오차를 계산합니다.
$$ f(w) = \frac{1} {N} \sum_{i = 1}^{n} g^{(i)}(y(x^{(i)}, w), t^{(i)}) \quad \text{(} x^{(i)} \text{: i번째 dataset, } t^{(i)} \text{: i번째 truth value,} $$
$$ \text{g: 오차의 제곱, y: x와 w의 선형 식)} $$
선형성에 의해,
$$ \frac{\partial f} {\partial w} = \frac{1} {N} \sum_{i = 1}^{n} \frac{\partial g} {\partial w} $$
이므로 gradient를 계산하기 위해 모든 training set을 확인해야 합니다. 이러한 트레이닝을 batch training이라 합니다. training set의 크기가 클수록 w값의 업데이트는 늦어질 것입니다.
Stochastic Gradient Descent(확률적 경사 하강)
SGD라 줄여서 부르기도 하는 이 방법은 gradient 계산을 위해 모든 training set을 보지 않습니다. training dataset의 내용들이 모두 동일한 확률로 선정될 수 있다고 할 때, 하나의 dataset만을 골라서 계산합니다.
$$ w = w - \alpha * \frac{\partial g^{(i)}} {\partial w} \quad \text{(i: 선택된 dataset의 idx)} $$
따라서 w의 업데이트 속도는 Gradient Descent 방법보다는 빠릅니다.
하지만 이 방법에도 문제는 존재합니다. 하나씩 뽑고 계산하는 것이므로 뽑힌 하나의 데이터가 전체를 대표한다고 확신할 수 없습니다. 그리고 선택된 데이터가 노이즈인 경우, 이 경우에도 계산이 진행되어 SGD는 깔끔하게 최적의 값으로 향하지 않습니다.
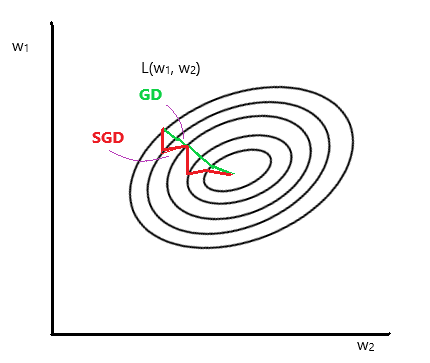
그래서 여기서 개선된 방법이 있습니다. 하나만 고르는 것이 아닌 전체 training dataset의 크기보다 작은 크기만큼 데이터들을 골라서 이들에 대해 gradient 계산을 실행합니다. training dataset의 크기보다 작은 크기만큼 데이터들을 mini-batch라 부르기도 합니다. 이 mini-batch의 크기는 hyper parameter 값으로 저희가 직접 설정해야 합니다.
'개념 정리 > 머신러닝 & 딥러닝 & A.I' 카테고리의 다른 글
| Computational Graph(연산 그래프) (0) | 2022.11.25 |
|---|---|
| 규제(Regularize) (0) | 2022.11.25 |
| 인공지능과 기계 학습 (0) | 2022.10.09 |
| CNN(Convolutional Neural Network) (0) | 2022.08.29 |
| 로지스틱 회귀(Logistic Regression) (0) | 2022.08.02 |



