
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Regression
- python3
- 데이터베이스
- db
- LSTM
- C++
- Seq2Seq
- 스택
- gan
- OS
- 운영체제
- 국민대학교
- kmu
- GIT
- 머신 러닝
- Heap
- 회귀
- PANDAS
- googleapiclient
- 파이썬
- instaloader
- Python
- programmers
- SQL
- 프로그래머스
- 재귀
- 정렬
- machine learning
- Stack
- 국민대
- Today
- Total
정리 노트
규제(Regularize) 본문
이 포스트는 국민대학교 소프트웨어학부 '컴퓨터 비전' 강의와 '인공지능' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다!
모델을 학습시킬 때 항상 overfitting(과적합)에 대해 생각해야 합니다. Overfitting 현상을 막는 방법은 여러 가지가 있고, 이 글에서는 규제에 대해 얘기하려 합니다.
규제 기법들도 여러 가지가 존재합니다.
- 가중치 벌칙(L1 norm, L2 norm 사용)
- Dropout
- 조기 멈춤(Early stopping)
- 데이터 확대: 매우 큰 훈련 집합을 사용(데이터 수집은 비용이 많이 듦) -> 가지고 있는 데이터를 인위적으로 변형
- 앙상블 기법: 여러 가지 모델들을 사용하는 방법
Regularizer
Regularizer는 loss 함수에 붙는 추가적인 항으로 이 regularizer를 통해 모델이 overfitting 되는 것을 막습니다. 따라서 regularizer까지 붙은 새로운 loss function(L)을 다음과 같이 적을 수 있습니다.
N: 학습할 데이터의 개수, W: 학습할 파라미터들이 있는 행렬, f: 우리의 모델
이 식의 모양에서 알 수 있듯이, 이제 모델이 학습할 때 loss function의 값을 최소화하기 위해서는 loss값과, regularizer 값을 최소화하는 방향으로 학습될 것입니다. lambda가 붙은 항이 regularizer입니다. Lambda는 regularization strength로 저희가 직접 정하는 하이퍼 파라미터입니다.
대표적인 regularizer로 L1 regularization, L2 regularization, Elastic net 등이 있습니다. 이 방법들은 여러 규제 방법들 중 가중치에 따라 페널티를 부여하는 방법입니다.
L1 Regularization(Lasso regression)
L1 regularization은 loss 값에 가중치들의 L1 norm을 더해주는 규제 방법입니다. 이를 식으로 표현하면 다음과 같습니다.
하지만 L1 규제 방법보다 L2 규제 방법을 쓸 때 더 성능이 좋기 때문에 자주 쓰이지 않는다고 합니다.
예를 들어, loss function을 퍼셉트론 목적 함수의 형태로 정의해봅시다.
이 함수를 하나의 가중치에 대해서 미분해봅시다.
따라서 가중치 갱신은 아래와 같이 이루어집니다.
alpha: learning rate, sign: 음수면 -1, 양수면 1을 반환하는 함수
이 식에서 yx는 가중치가 갱신될 방향, exp는 얼만큼얼마큼 틀렸는지, alpha * lambda * sign은 규제를 얼마큼 적용하는지 나타내는 항입니다. 만약 가중치 값이 양수였다면 상수 값만큼 감소하는 방향으로 갱신될 것이고, 가중치 값이 음수였다면 상수 값만큼 증가하는 방향으로 갱신될 것입니다. 여기서 가중치의 값이 뭐였는지 중요하지 않습니다.
L2 Regularization(Ridge regression)
L2 regularizatoin은 loss 값에 가중치들의 L2 norm을 더해주는 규제 방법입니다. 이를 식으로 표현하면 다음과 같습니다.
L1 regularization에서 정의한 목적 함수에 L2 규제(여기서는 L2 norm의 제곱)를 적용해봅시다.
여기서 lambda 값을 2로 나눠준 이유는 계산하기 편하려고 했습니다. 이 식을 하나의 가중치에 대해 미분하면 아래와 같은 식을 얻을 수 있습니다.
따라서 가중치 갱신은 아래와 같이 이루어집니다.
L1 regularization 부분에서와 같이 이 식을 해석하면 L1 때와의 차이점을 알 수 있습니다. 여기서는 전과는 다르게 가중치의 크기가 가중치 갱신에 영향을 끼칩니다. 만약 가중치가 양수였다면 가중치에 비례해서 감소하는 방향으로 갱신되고, 가중치가 음수였다면 가중치에 비례해서 증가하는 방향으로 갱신됩니다.
Elastic net regularization
L1 regularization과 L2 regularization을 합친 규제 방법입니다. 이를 식으로 표현하면 다음과 같습니다.
두 규제 방법이 합쳐져서 하이퍼 파라미터가 2개로 늘어났습니다.
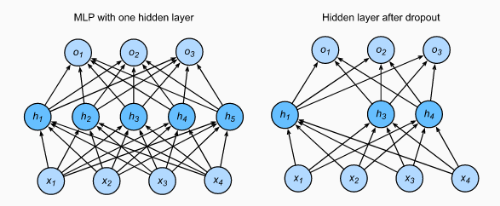
Dropout
가중치의 크기를 이용해 규제하는 방법 말고도 여러 방법들이 있습니다. 예를 들어 dropout은 저희가 정한 확률만큼 은닉 층의 일부 노드를 동작하지 않게 하는 방법입니다. 역전파 단계가 진행될 때에도 동작하지 않은 은닉 층의 노드들에 대한 gradient도 적용되지 않습니다.( https://ko.d2l.ai/chapter_deep-learning-basics/dropout.html )
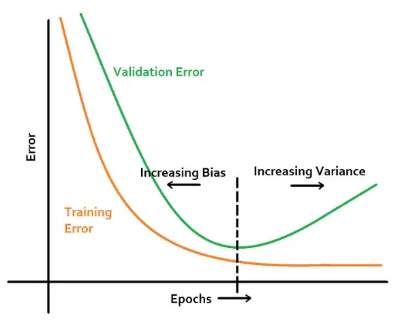
Early Stopping
다른 방법으로 조기에 학습을 멈추는 방법도 있습니다. 이 방법은 모델을 학습할 때 validation set을 사용해서 validation dataset에 대한 정확도가 n epoch 이후로 늘어나지 않는다면 학습을 중단시키는 방법입니다.
'개념 정리 > 머신러닝 & 딥러닝 & A.I' 카테고리의 다른 글
| 배치 정규화(Batch Normalization) (0) | 2022.12.04 |
|---|---|
| Computational Graph(연산 그래프) (0) | 2022.11.25 |
| 확률적 경사 하강(SGD) (0) | 2022.10.20 |
| 인공지능과 기계 학습 대한 간단한 소개 (0) | 2022.10.09 |
| CNN(Convolutional Neural Network) (0) | 2022.08.29 |



