
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- PANDAS
- 국민대
- Stack
- db
- 재귀
- GIT
- 프로그래머스
- 스택
- Heap
- SQL
- C++
- machine learning
- LSTM
- Seq2Seq
- 정렬
- Regression
- instaloader
- python3
- Python
- 운영체제
- programmers
- 머신 러닝
- 파이썬
- 회귀
- kmu
- 데이터베이스
- 국민대학교
- OS
- googleapiclient
- gan
- Today
- Total
정리 노트
선형 회귀(Linear Regression) 본문
이 포스트는 국민대학교X프로그래머스 주관하는 '2022학년도 여름방학 인공지능 온라인 실전 부트캠프'에서 배운 내용을 정리하는 포스트입니다.
회귀?
회귀는 특정 데이터가 주어졌을 때 결과를 예측하는 지도 학습의 유형입니다. 특정 데이터들을 학습해서 데이터를 설명할 수 있는 가장 합리적인 선형 함수를 찾아내는 접근 방법이 선형 회귀 법(Linear Regression)입니다. 선형 회귀에서 학습할 데이터들은 아래와 같다고 합시다.
| 하루 평균 공부 시간(단위: Hour, 범위: 0 ~ 24 사이의 실수) | 시험 점수(0 ~ 100 사이의 실수) |
| 0.5 | 40 |
| 1 | 55 |
| 1.5 | 65 |
| 2 | 74 |
| 2.5 | 88 |
| 3 | 95 |
이 데이터를 학습한 선형 회귀 모델에 공부한 시간을 넣으면 시험 점수가 얼마나 나올지 예측해주는 선형 회귀 모델을 만들어 봅시다.
1. 가설 세우기
위의 데이터를 언뜻 보면 공부 시간과 시험 점수는 비례 관계를 가지고 있다고 볼 수 있습니다. 실제로 이 데이터를 그래프로 그리면 아래와 같습니다.
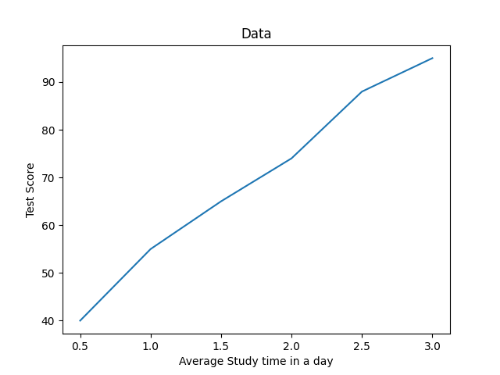
데이터들이 거의 선형을 띠고 있으므로 선형 회귀 모델에 학습시키기 적당합니다. 선형 함수는 y = ax + b처럼 생겼습니다. 저희의 가설 함수도 선형 함수와 같은 모양으로 만들 수 있습니다. 저희가 만들 선형 회귀 모델을 H라 하면, H(x) = Wx + b로 만들 수 있습니다. 이제부터 H가 저희가 학습시킬 선형 회귀 모델입니다.
2. 선형 회귀 모델의 학습 과정
선형 회귀 모델은 학습을 통해 가장 합리적인 W와 b값을 찾는 것을 목적으로 합니다. 하지만 선형 회귀 모델로 학습한 결과는 실제 결과와 차이가 날 수 있습니다. 예를 들어 모델이 학습해서 얻은 결과로 W = 10, b = 40라고 합시다. 실제 결과와 모델을 비교하면 아래와 같습니다.
| 하루 평균 공부 시간(x) | 시험 점수(y) | 모델 예측 점수(H(x) = 10x + 40) |
| 0.5 | 40 | 45 |
| 1 | 55 | 50 |
| 1.5 | 65 | 55 |
| 2 | 74 | 60 |
| 2.5 | 88 | 65 |
| 3 | 95 | 70 |

이 학습 결과는 실제 값과 딱 봐도 많은 차이가 있습니다. 가장 이상적인 W, b값을 찾기 위해서는 실제 값과의 차이를 최소한으로 만들어야 합니다. 여기서 실제 값과 모델의 예측 값과의 차이가 이 가설(모델)이 얼마나 정확한지 판단하는 기준이 되며 주로 비용(Cost)이라 부릅니다.
비용 함수(Cost Function)
간단하게 생각하면 비용의 정의는 '실제 값과 모델 예측 값의 차이의 평균'이라 생각할 수 있습니다. 주로 여기서 사용하는 비용 함수는 '실제 값과 모델 예측 값의 차이의 제곱의 평균'(Mean Squared Error, MSE)을 사용합니다. 비용 함수를 cost라 할 때, MSE를 식으로 나타내면,
cost(W, b) = 1/m∑(H(xi) - yi)**2(m은 데이터의 개수, i는 1부터 m사이의 자연수)로 나타낼 수 있습니다.
이 식을 최소화 할 수 있는 W와 b값을 찾아야 합니다. 이 비용 함수를 위의 예제에 적용해보면 비용은,
((45 - 40)**2 + (50 - 55)**2 + (55 - 65)**2 + (60 - 74)**2 + (65 - 88)**2 + (70 - 95)**2)) / 6 = 1560 / 6 = 260...!
엄청난 비용입니다...
경사 하강(Gradient Descent)
비용 함수의 최솟값을 찾으려면 함수의 미분을 사용해야 합니다. 저희의 모델은 W, b 두 가지 값에 의해 좌우되기 때문에 W에 대한 편미분, b에 대한 편미분을 시행해야 합니다.
∂cost/∂W = 1/m*∂(∑(H(xi) - yi)**2)/∂W = 1/m*∂(∑(W*xi + b - yi)**2)/∂b = 2/m * (∑(W*xi + b - yi) * xi)
∂cost/∂b = 1/m*∂(∑(H(xi) - yi)**2)/∂b = 1/m*∂(∑(W*xi + b - yi)**2)/∂b = 2/m * ∑(W*xi + b - yi)
저희의 경우, ∂cost/∂W = 1/3 * (-178) = -59.3333...이고 ∂cost/∂b = -72입니다.
그리고 이 값을 이용해 새롭게 W, b값을 수정합니다.
W = W - a * 2/m∑(W*xi + b - yi) * xi(a는 learning_rate로 값이 변하는 비율을 조정)
b = b - a * 2/m∑(W*xi + b - yi)(a는 learning_rate로 값이 변하는 비율을 조정)
a를 0.001이라 할 때 저희의 경우, W = 10 - 0.001 * (-59.3333.....) = 10.059333...이고, b = 40 - 0.001 * (-72) = 40.072입니다.
결과를 그래프로 표현하면 아래와 같습니다.
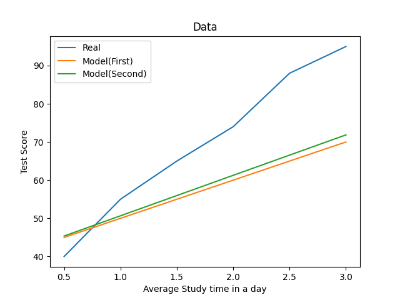
이 과정이 경사 하강 방법(Gradient Descent) 이루어지는 과정입니다.
수정된 W, b값을 통해 비용을 계산하고 경사 하강을 통해 다시 W, b값을 수정하는 과정이 선형 회귀 모델이 학습하는 과정입니다.
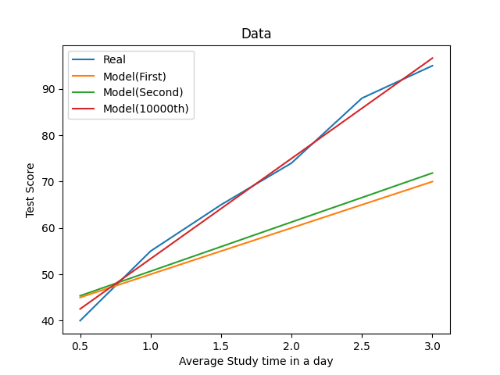
다변수 선형 회귀
지금까지는 변수가 1개(하루 평균 공부 시간)인 경우의 선형 회귀를 보았습니다. 여러 변수들이 있는 다변수 선형 회귀 방법도 변수가 하나일 때와 비슷합니다.
다변수 선형 회귀에서는 가설(H(x))을 H(x) = w1*x1 + w2 *x2 + ... + wn*xn + b(n은 자연수) 모양으로 만들게 됩니다. 그리고 똑같이 비용이 최소화되는 방향으로 학습을 거치게 됩니다.
(2022.10.22. 토요일 추가)
Overfitting & Underfitting
가설(H(x))에 학습시킬 파라미터(위에 있는 w1, w2, b 같이 학습하면서 변화하는 값들)를 많이 설정할수록 더욱더 정확하게 데이터를 학습할 수 있을 것입니다. 하지만 그렇다고 무턱대도 파라미터들을 많이 설정할 수 없습니다. 왜냐 하면, 컴퓨터 자원은 무한하지 않습니다. 파라미터가 많아질수록 파라미터를 학습하는데 필요한 시간, 용량 등의 자원들이 더 많이 소모됩니다. 그리고 파라미터를 많이 설정할수록 훈련 데이터 집합들에 대해서만 완벽하게 맞춰지는 문제가 생깁니다. 너무 훈련 데이터 집합에 완벽하게 맞춰져서 새로운 데이터 집합이 들어왔을 때 이 데이터와 훈련된 모델의 예측 값의 오차가 커지는 상황이 발생할 수 있습니다. 이러한 상황을 overfitting(과적합)이라고 합니다. 이러한 모델은 variance가 크다고 얘기하기도 합니다. 주로 이런 상황에서는 variance를 낮추기 위해 데이터를 더 모아서 학습을 더 진행시킵니다.
그러면 필요한 파라미터 수를 많이 줄이면 학습에 소모되는 시간도 적어지고 overfitting 문제를 피할 수 있을 것입니다. 하지만 파라미터 수가 적은 것도 좋지 않습니다. 파라미터 수가 너무 적으면 주어진 훈련 데이터 집합에 대해서도 학습이 제대로 이루어지지 않을 수 있습니다. 이러한 상황을 underfitting이라고 합니다. 이러한 모델은 bias가 크다고 얘기하기도 합니다. 주로 이러한 상황에서는 bias를 낮추기 위해 모델의 파라미터 수를 늘려줍니다.
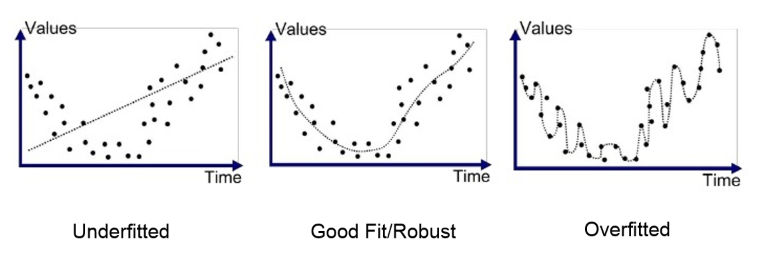
이렇듯, 파라미터의 수를 결정하는 데 있어서 bias와 variance가 tradeoff 관계에 위치하게 됩니다. 따라서 모델을 설계할 때 파라미터의 수는 그동안의 경험을 바탕으로 알아서 적당히 잘 설정해야 합니다.
'개념 정리 > 머신러닝 & 딥러닝 & A.I' 카테고리의 다른 글
| 규제(Regularize) (0) | 2022.11.25 |
|---|---|
| 확률적 경사 하강(SGD) (0) | 2022.10.20 |
| 인공지능과 기계 학습 (0) | 2022.10.09 |
| CNN(Convolutional Neural Network) (0) | 2022.08.29 |
| 로지스틱 회귀(Logistic Regression) (0) | 2022.08.02 |



