
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- OS
- SQL
- instaloader
- db
- LSTM
- C++
- 재귀
- 스택
- Stack
- 파이썬
- 머신 러닝
- GIT
- programmers
- googleapiclient
- 회귀
- python3
- 프로그래머스
- 정렬
- 국민대학교
- 국민대
- Seq2Seq
- Regression
- 데이터베이스
- gan
- PANDAS
- Heap
- machine learning
- kmu
- Python
- 운영체제
- Today
- Total
정리 노트
관계 데이터 연산 - 확장된 관계 연산자 본문
이 포스트는 아래의 포스트 내용과 이어집니다.
관계 데이터 연산 - 순수 관계 연산자
이 포스트는 아래의 포스트의 내용과 이어집니다. 관계 데이터 연산 - 집합 연산자 이 포스트는 국민대학교 소프트웨어학부 '데이터베이스' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보
study-note-99.tistory.com
Semi-join(⋉)
R(X), S(Y)의 조인 속성을 X \( \cap \) Y라고 할 때, S와 join 할 수 있는 R의 tuple들의 집합이 semi-join 연산의 결과입니다. 이를 S에서 R로의 semi-join이라 부릅니다. 이를 식으로 적으면 아래와 같습니다.
$$ R ⋉ S = R \Join_{N} ( \Pi_{X \cap Y}(S) ) = \Pi_{X}(R \Join_{N} S) $$
예를 들어, R(X), S(Y)가 아래와 같을 때 R ⋉ S의 결과는 아래의 그림과 같습니다.
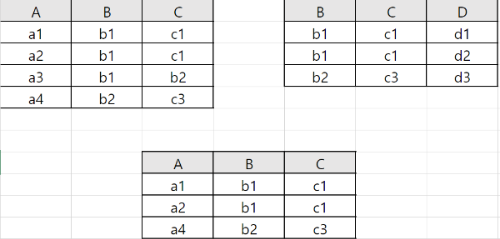
위 예시에서 조인 속성(X \( \cap \) Y)은 {B, C}(<b1, c1>, <b2, c3>) 입니다. 따라서 R ⋉ S 연산을 실시하면 <b1, c1>, <b2, c3>를 포함하는 테이블 R에서의 행들을 모두 포함한 테이블이 연산의 결과로 나옵니다. 만약 S ⋉ R(R에서 S로의 semi-join)로 뒤집어서 연산을 진행하면 결과는 달라집니다. <b1, c1>, <b2, c3>를 포함하는 테이블 S에서 튜플을 고르는 방향으로 연산이 진행되기 때문입니다.
Semi-join은 분산 처리를 위해 DBMS가 내부적으로 실행하는 연산입니다. 예를 들어 R이 서울에 있고 S가 부산에 있다고 합시다. 만약 서울에서 R \( \Join \) S을 진행하려 한다면 아래의 식에 따라 연산해야 합니다.
$$ \begin{align} R \Join_{N} S &= (S ⋉ R) \Join_{N} R = ( S \Join_{N} (\Pi_{X \cap Y}(R)) ) \Join_{N} R \\ &= T_{부산, 서울}(S \Join_{N} (T_{서울, 부산}(\Pi_{X \cap Y}(R))) \Join_{N} R \end{align} $$
여기서 \(T_{a, b}\)는 a에서 b로 전송하는 연산을 의미합니다.
이 연산은 일반 사용자에게는 제공하지 않는 연산이므로 SQL에서 제공하지 않습니다.
외부 조인(Outer Join, \( \Join^{+} \))
R(X), S(Y)를 조인할 때 한 릴레이션에 있는 tuple에 대해 상대 릴레이션에 대응하는 tuple이 없을 경우, 상대를 null tuple로 만들러 결과 릴레이션에 포함하는 연산입니다. 이 연산은 바로 예시를 통해 보겠습니다.
R(X), S(Y)가 아래와 같을 때, 외부 조인을 실행할 때의 결과는 아래의 그림과 같습니다.
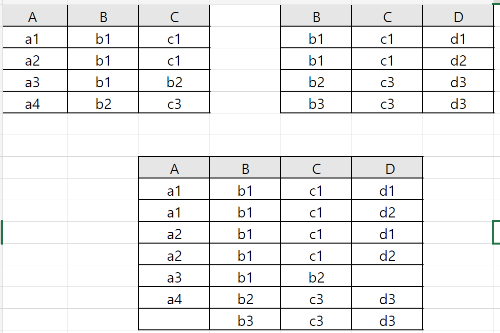
테이블 R에서 3번째 행의 <b1, b2>는 조인 연산을 할 때 테이블 S에서 대응되는 tuple이 없습니다. 따라서 결과 테이블에는 null 표시를 합니다. 테이블 S에서 마지막 행의 <b3, c3>도 같은 이유로 대응되지 못 한 부분에 null 표시를 합니다.
그리고 이 연산을 통해 두 테이블 R, S의 모든 tuple이 결과 테이블에 포함되는 것을 볼 수 있습니다.
외부 조인은 driving table을 누구로 지정하느냐에 따라 2가지로 나뉠 수 있습니다.
- Left outer join(\( \Join^{+}_{L} \)): 두 릴레이션 R, S 중 R을 driving table로 하는 outer join
- Right outer join (\( \Join^{+}_{R} \)): 두 릴레이션 R, S 중 S를 driving table로 하는 outer join
두 조인 결과를 그림으로 보면 아래와 같습니다.

이를 통해 두 결과를 합친 결과 테이블이 위에서 본 outer join의 결과 테이블과 같은 것을 알 수 있습니다.
$$ (R \Join^{+}_{L} S) \cup (R\Join^{+}_{R} S) = R \Join^{+} S $$
외부 합집합(Outer Union, \( \cup^{+} \))
차수(속성의 수)는 동일하지만 합칠 수 없는(부분적으로는 합칠 수 있는) 두 릴레이션을 합치는 연산으로 결과 릴레이션의 차수를 확장시켜 두 릴레이션의 합집합으로 만듭니다.
R(X), S(Y)가 아래와 같을 때, 외부 합집합을 실행할 때의 결과는 아래의 그림과 같습니다.
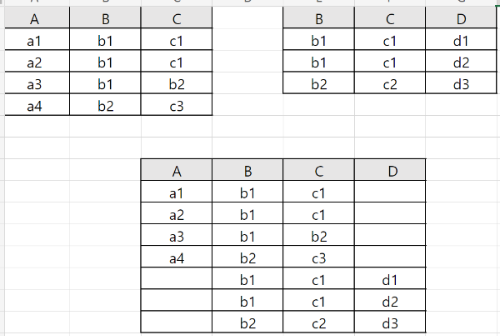
B, C 속성은 R과 S 모두 가지고 있는 속성이므로 두 속성은 합친 것을 확인할 수 있습니다. 조인과 다르게 두 덩어리를 합친 듯한 결과가 나오는 것에 주의해야 합니다.
그룹 연산(Group Operator)과 집단 함수(Aggregate Function)
그룹 연산을 하면 테이블 안에서 기준 속성 값이 같은 tuple끼리 묶습니다. 만들어지는 그룹의 개수는 연산을 실행하기 전까지 알 수 없습니다. 이는 기준 속성 값을 기준으로 정렬한 것과 같은 효과를 가집니다.
주로 group 연산을 아래와 같은 식으로 표현합니다.
$$ GROUP_{\text{기준 속성}}(\text{대상 테이블}) $$
주로 통계 함수들을 집단 함수라 표현합니다. 집단 함수들은 여러 개의 입력을 받아 하나의 출력을 내보내는 특징을 가지고 있습니다.
집단 함수를 group 연산의 결과에 적용할 때 2가지 사항에 주의해야 합니다.
- NULL 값이 들어있는 tuple은 계산에서 제외됨
- 중복 값이 있는 tuple은 제외되지 않음
일반적으로 그룹 연산과 집단 함수를 같이 사용하면 아래와 같은 형식을 가집니다.
$$ F_{B}(GROUP_{A}(E)) $$
- E: 대상 테이블
- F: 집단 함수(ex. COUNT, SUM, MIN, MAX, ...)
- A: 그룹 연산의 기준 속성
- B: 집단 함수의 기준 속성
대상 테이블에 그룹 연산을 먼저 적용하고 각 그룹에 대해 집단 함수를 적용한 결과를 가지게 됩니다.
'개념 정리 > 데이터베이스' 카테고리의 다른 글
| [MySQL]SELECT문 WHERE절 (4) | 2024.02.28 |
|---|---|
| [MySQL]SELECT문 (2) | 2024.02.08 |
| 관계 데이터 연산 - 순수 관계 연산자 (0) | 2023.10.20 |
| 관계 데이터 연산 - 집합 연산자 (0) | 2023.09.13 |
| 관계 데이터 구조 (0) | 2023.08.10 |

