
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- programmers
- Python
- 파이썬
- 스택
- googleapiclient
- 국민대
- 머신 러닝
- 정렬
- 회귀
- gan
- 재귀
- Stack
- 프로그래머스
- OS
- instaloader
- Regression
- python3
- 운영체제
- Seq2Seq
- PANDAS
- LSTM
- SQL
- 국민대학교
- C++
- kmu
- 데이터베이스
- GIT
- Heap
- machine learning
- db
- Today
- Total
정리 노트
표본 오차와 신뢰 구간 본문
이 포스트는 아래의 책의 내용을 정리하며 작성한 포스트입니다. 여기서 사용되는 예시 또한 책의 예시를 사용합니다.
통계 101×데이터 분석 | 아베 마사토 - 교보문고
통계 101×데이터 분석 |
product.kyobobook.co.kr
표본 오차
평균이 \( \mu \)인 모집단에서 표본을 얻는다고 합시다. 이 표본들의 평균을 계산해 모집단의 평균을 추측하려 합니다. 만약 이 표본 평균이 모평균과 같은 값을 가진다면 모집단을 알게 된다는 것입니다.
하지만 이럴 가능성은 거의 없습니다. 일반적으로 모평균과 표본 평균은 일치하지 않습니다. 이런 오차를 표본 오차(표집 오차, sampling error)라 합니다. 이러한 오차는 모집단에서 표본을 선택하는데 발생하는 피할 수 없는 오차입니다.
표본 오차는 평균을 계산할 때뿐만 아니라 다양한 통계량에서 발생할 수 있습니다.
이 책에서는 주사위를 굴리는 것을 예로 들었습니다. 이상적인 정육면체 주사위를 모집단이라 가정할 때 1 ~ 6의 눈은 각각 1/6의 확률로 나옵니다. 따라서 모평균은 (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.5입니다(\( \mu \) = 3.5).
주사위를 굴리는 행동을 6번 진행(표본 수 = 6)해서 표본 평균을 계산하는 일을 3번 진행한 결과 아래와 같습니다.
- 표본 = {4, 3, 2, 5, 6, 3}, 표본 평균 = 약 3.83
- 표본 = {1, 2, 1, 2, 6, 4}, 표본 평균 = 약 2.67
- 표본 = {4, 5, 6, 1, 5, 5}, 표본 평균 = 약 4.33
이 때 표본 오차는 각각 0.33, 0.83, 0.83씩 생깁니다.
이처럼 표본 집단이 모집단의 성질과 정확히 일치하기 매우 힘듭니다. 그러나 이 오차에 대해 더 파고들어 생각해야 하는 것이 바로 통계학입니다.
큰 수의 법칙(Law of large numbers)
표본 평균과 모집단 평균 사이에는 큰 수의 법칙이 성립합니다. 표본 크기가 커질수록 표본 평균과 모집단 평균의 차이가 줄어든다는 것이 큰 수의 법칙입니다. 즉, 표본 오차를 줄일 수 있습니다.
아래 그래프는 표본의 크기를 1부터 1000까지 늘려가며 주사위 값의 표본 평균을 계산한 결과를 나타내는 그래프입니다.

이 그래프를 보면 주사위를 많이 굴릴수록 표본 평균의 값이 모집단의 평균에 수렴하는 것을 확인할 수 있습니다. 하지만 이는 무한히 주사위를 굴리면 모집단의 평균과 같아진다는 이야기는 아닙니다.
만약, 특정 표본 크기일 때의 표본 오차 값을 짐작할 수 있다면, 이는 표본 오차의 확률 분포를 추측할 수 있는 것으로 어느 정도의 오차가 어떤 확률로 나타나는지 알 수 있게 됩니다.
중심극한정리(Central limit theorem)
중심 극한 정리는 표본 오차의 분포에 관한 중요한 정보를 제공합니다. 이 정리는 분산이 무한히 발산하는 분포를 제외한 어떤 모집단의 분포이든 간에 표본 크기가 커질수록 표본 평균의 분포는 정규 분포로 근사할 수 있다는 정리입니다.
주사위 값의 표본 평균을 구하는 과정을 수없이 진행해서 나온 표본 평균들의 분포들을 그려보면 아래와 같습니다.
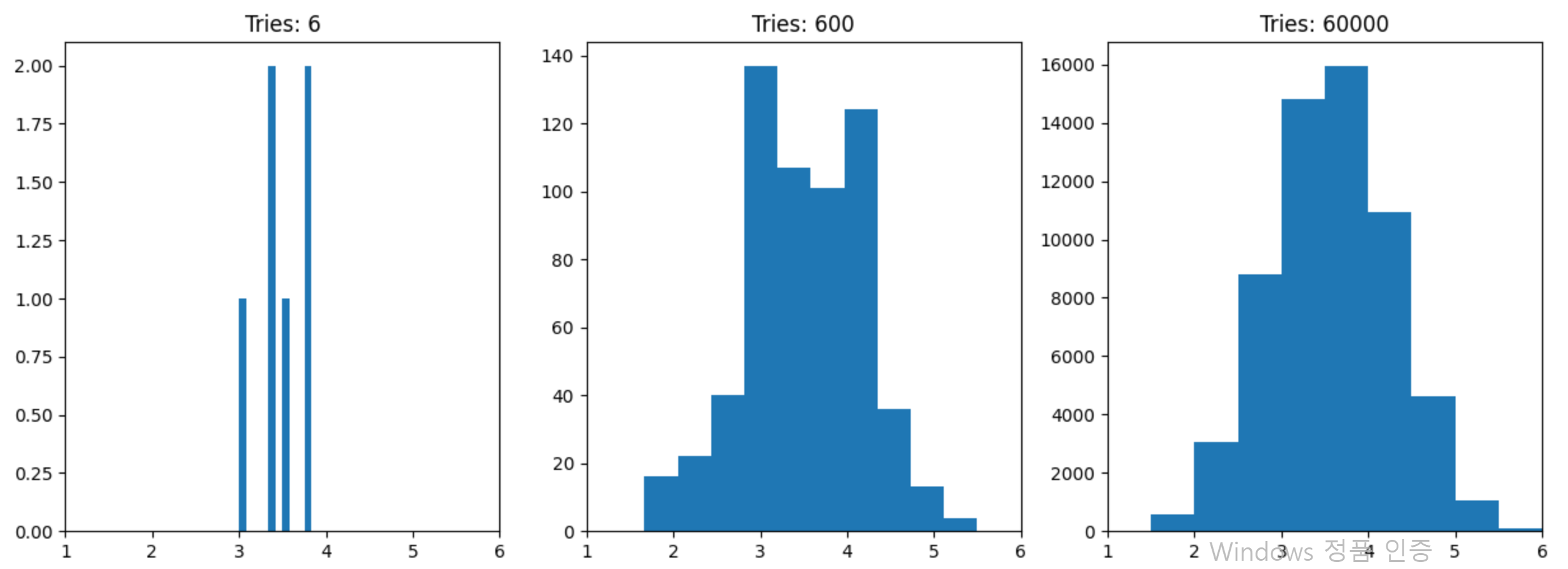
시행 횟수가 늘어날수록 표본 평균들의 분포가 정규 분포의 모양과 유사해지고 있음을 볼 수 있습니다.
정규 분포는 평균과 표준 편차라는 2가지의 수를 알면 분포의 형태, 위치가 하나로 결정되고, 각 값이 어느 확률로 나올지 알 수 있습니다. 표본 평균의 분포를 이러한 정규 분포에 근사한다면 이 분포의 평균과 표준 편차는 각각 모집단의 평균(\( \mu \))과 모집단의 표준 편차를 표본의 크기에 루트를 씌운 값(\( \sigma \over \sqrt{n} \))으로 나눈 값으로 나타낼 수 있습니다.
그러면, 표본 오차의 분포는 분포 전체를 모집단의 평균만큼 평행 이동한 것이므로, 표본 오차 분포의 평균은 0이라고 할 수 있습니다. 그리고 표준 편차는 그대로입니다. 즉 표본 오차의 분포를 알기 위해서는 모집단의 표준 편차와 표본의 크기 2가지가 필요합니다. 하지만 모집단의 표준 편차는 모집단의 성질, 미지수이기 때문에 표본에서 추정한 표준 편차 (\(s \over \sqrt{n} \)) 를 대신 사용합니다.
(사실 이 분포는 t분포의 모양에 매우 가깝지만 지금은 정규 분포의 모양으로 이야기를 진행합니다.)
신뢰 구간
몇 퍼센트의 신뢰 구간이라는 말은 몇 퍼센트의 확률로 이 구간 안에 모집단의 평균이 들어있다는 말입니다. 예를 들어 95%의 신뢰 구간은 이 신뢰 구간을 계산하는 작업을 100번 시행할 때 모집단 평균이 이 구간 안에 95번 들어간다는 의미를 가집니다.
정규 분포에서는 (평균) \( \pm \) 1.96 * (표준 편차) 범위 안에 약 95%의 값들을 포함하고 있습니다. 즉, 정규 분포에서 하나의 값을 임의로 선택하면 이 값이 95%의 확률로 이 범위 안에 속합니다. 이 식을 사용하면 표본 오차의 약 95%가 어느 정도로 나타나는지 범위로 표시할 수 있습니다.
$$ 0 - 1.96 * {s \over \sqrt{n}} \leq \bar{x} - \mu \leq 0 + 1.96 * {s \over \sqrt{n}} $$
$$ \bar{x} - 1.96 * {s \over \sqrt{n}} \leq \mu \leq \bar{x} + 1.96 * {s \over \sqrt{n}} $$
예를 들어 10명의 키에 대한 표본을 얻었다고 합시다. 표본 값은 아래와 같습니다.
179, 176, 166, 167, 170, 164, 170, 154, 169, 164
이 표본들로 표본평균(167.9)과 비편향표준편차(6.89)를 계산할 수 있습니다. 따라서 95%의 신뢰 구간은 163.54 ~ 172.26으로 계산됩니다. 위 표본은 모집단의 평균이 170인 집단에서 표본을 추출했습니다. 모집단의 평균이 신뢰 구간 안에 있는 것을 확인할 수 있습니다.
추정량
위에서 얘기한 비편향표준편차를 이해하기 위해 추정량부터 이해할 필요가 있습니다. 추정량은 모집단의 성질을 추정하는 데 사용하는 통계량을 의미합니다. 표본의 크기를 무한대로 했을 때 모집단의 성질과 일치하는 추정량을 일치추정량이라 하고, 추정량의 평균이 모집단의 성질과 일치하면 비편향추정량이라 부릅니다. 비편향추정량은 모집단의 성질을 과대, 과소하지 않게 나타내는 양입니다.
표본표준편차의 계산식에서 분모는 표본 수입니다. 기술통계에서는 문제가 없지만 이 계산은 모집단의 표준편차를 과소평가한다는 문제가 있습니다. 책에서 이에 대한 직감적인 설명을 아래와 같이 합니다.
각 값과 모집단의 평균의 차이를 제곱하여 값이 얼마나 퍼졌는지 측정해야 합니다만 모집단의 평균이 미지수이므로 모집단의 평균 대신, 표본평균을 사용한 것입니다. 그리고 표본평균과 모집단의 평균은 일치하지 않고, 각 값과 모집단의 위치 관계 또는 각 값과 표본평균의 위치 관계를 생각하면, 하나의 값은 모집단보다는 표본평균에 가까이 위치할 것입니다. 그러므로 각 값과 표본평균의 차이를 제곱한 값들의 합이 모집단의 평균과의 차이를 제곱한 값들의 합보다 작은 값이 됩니다. 따라서 표본 수로 나누지 않고 표본 수에서 1을 뺀 값으로 나눠 과소평가를 보정합니다.
올바르게 계산하기 위해서는 (표본 수 - 1)로 나눠야 모집단의 표준편차의 비편향추정량이 됩니다. 이 계산 결과가 비편향표준편차입니다.
t 분포
중심극한정리는 표본의 수가 커질 수록 근사하게 성립하는 것이라 작은 표본일 때 정규 분포로 근사할 수 없는 경우가 생깁니다. 이때 t 분포를 사용합니다. 이 분포는 전체 모집단이 정규 분포라는 가정 하에 모집단의 표준편차를 표본으로 계산한 비편향표준편차(s)로 대치했을 때 표본평균에서 모집단의 평균을 뺀 값을 \( s \over \sqrt{n} \)로 나누어 표준화한 값이 따르는 분포입니다.
$$ {\bar{x} - \mu} \over {s / \sqrt{n}} $$
이 분포는 정규 분포와 매우 유사한 형태를 가지고 표본 크기에 따라 조금씩 모양이 달라집니다. 그래도 신뢰 구간을 구하는 과정은 동일하게 적용됩니다. 표본의 크기가 커질수록 t 분포는 정규 분포에 가까워집니다.
'개념 정리 > 통계' 카테고리의 다른 글
| 비율의 비교(이항과 카이제곱) (2) | 2024.01.25 |
|---|---|
| 대푯값의 비교(t 검정, 분산 분석) (1) | 2024.01.11 |
| 진실과 판단의 4가지 패턴 (1) | 2024.01.04 |
| 가설 검정의 계산 (1) | 2024.01.01 |
| 가설 검정의 원리 (1) | 2023.10.27 |

