
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Stack
- 회귀
- 국민대학교
- 운영체제
- googleapiclient
- Regression
- 프로그래머스
- LSTM
- python3
- machine learning
- 재귀
- 머신 러닝
- Python
- SQL
- db
- 파이썬
- gan
- 정렬
- kmu
- Heap
- Seq2Seq
- PANDAS
- programmers
- GIT
- OS
- 데이터베이스
- 스택
- C++
- instaloader
- 국민대
- Today
- Total
목록개념 정리 (76)
정리 노트
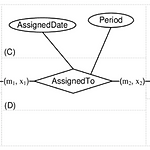 데이터베이스의 개념적 설계
데이터베이스의 개념적 설계
이 포스트는 국민대학교 소프트웨어학부 '데이터베이스' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! 개체-관계 모델 현실 세계의 개념적 표현한 것으로 모든 것을 개체(entity)와 관계(relationship)로 표현합니다. 개체의 타입은 속성으로 정의하고 개체 인스턴스들 중에서 유일하게 식별할 수 있는 값을 가지는 속성을 key 속성이라고 합니다. 아래의 그림을 보면 'Employee'라는 개체에 'Emp_No'와 'Name' 2개의 속성이 있음을 알 수 있고, 'Emp_No' 속성에 밑줄을 그어서 key 속성임을 표시하고 있습니다. 속성의 유형 속성은 여러 유형들을 가질 수 있습니다. 단순 / 복합: 아래의 '그림 2'..
이 포스트는 국민대학교 소프트웨어학부 '데이터베이스' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! 데이터베이스의 설계를 크게 3가지로 나눠서 봅니다. 개념적 설계: 현실 세계의 데이터를 entity 또는 relationship으로 표현 논리적 설계: entity와 relationship을 컴퓨터에 저장 물리적 설계: 디스크에 저장 데이터베이스 설계에서 사용하는 데이터 모델은 데이터의 개념적 표현을 제공하는데 이용되는 추상화의 한 형태로 아래의 3가지를 수학적으로 정의해야 합니다. 데이터 구조: 정적 성질, 개체 간의 관계 명세 제약 조건: 개체 instance에 대한 논리적 / 의미적 제약 명세 연산: 동적 성질, 개체 i..
 프로세스(Process)
프로세스(Process)
이 포스트는 국민대학교 소프트웨어학부 '운영체제' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! 프로세스의 정의 프로세스는 쉽게 말해 실행되고 있는 프로그램입니다. 출처: https://pages.cs.wisc.edu/~remzi/OSTEP/cpu-intro.pdf, 1페이지 The definition of a process, informally, is quite simple: it is a running program. 예를 들어 지금 이 블로그를 보고 있는 인터넷 브라우저도 프로세스, 게임도 프로세스, 음악을 재생하고 있는 프로그램도 프로세스입니다. 저희는 여러 프로그램들을 동시에 켜놓고 컴퓨터를 하고 있을 때가 많습니다..
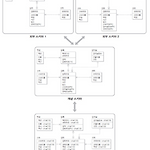 DBS(Database System)
DBS(Database System)
DBS는 DBMS을 사용해 개발한 응용 프로그램을 통해 관련 데이터를 관리하고 있는 시스템으로 DBMS와 아래 4가지로 구성되어 있습니다. 1. 데이터 스키마(Data schema) 스키마는 DB의 구조와 제약 조건의 명세입니다. 이는 테이블과 별개로 저장되기에 실제로 스키마와 레코드 인스턴스들(테이블)까지 합쳐서 데이터베이스라고 부릅니다. 스키마의 종류로 아래의 3가지가 존재합니다. 외부 스키마(external schema, subschema): 전체 DB의 일부분만을 기술하고 각 사용자의 입장에서 필요한 DB의 논리적 구조를 정의합니다. 개념 스키마(conceptual schema, schema): 모든 사람이 필요로 하는 데이터를 모은 전체 DB를 정의합니다. 일반적으로 얘기하는 스키마가 개념 스키..
이 포스트는 국민대학교 소프트웨어학부 '운영체제' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! 이번 포스트에서는 운영 체제를 공부한다면 기본적으로 알아야 할 3가지에 대해 소개하는 느낌으로 적었습니다. 1. 가상화(Virtualizing) 1-1. CPU 가상화(Virtualizing CPU) 아래에 C 언어로 작성한 간단한 코드가 있습니다. // Source: https://github.com/remzi-arpacidusseau/ostep-code/blob/master/intro/cpu.c #include #include #include "common.h" int main(int argc, char *argv[]) { i..
이 포스트는 국민대학교 소프트웨어학부 '데이터베이스' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! Database(DB) 관련된 데이터들의 집합을 의미하며, 아래 4가지의 개념을 만족해야 합니다. 공용 데이터(shared data): 여러 사람이 같이 사용할 수 있는 데이터야 합니다. 통합 데이터(integrated data): 중복된 데이터를 철저히 제거해야 하나, 중복을 의도해서 남겨야 할 때가 있는데 이 때는 최소화 해야 합니다. 그리고 이러한 중복에 대해 알고 있으며 컨트롤할 수 있어야 합니다. 저장 데이터(stored data): 컴퓨터가 접근할 수 있는 매체에 저장돼야 합니다. 운영 데이터(operational ..
이 포스트는 국민대학교 소프트웨어학부 '빅데이터최신기술' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! 문제 상황 크기가 N인 집합에 속한 원소들만 담은 스트림이 있다고 합시다. 이 스트림에서 서로 다른 원소들의 개수를 구하려면 집합을 만들어 스트림의 모든 아이템을 집합에 넣으면 됩니다. 집합은 동일한 아이템을 원소로 가지지 않기 때문에 이를 통해 쉽게 찾을 수 있습니다. 하지만 생성해야 할 집합의 크기가 너무 커져 메모리에 올릴 수 없는 정도라면 어떻게 찾아야 할까요? Flajolet-Martin(ver. 1) Flajolet-Martin 알고리즘을 통해 이를 대략적으로 구할 수 있습니다. 이 알고리즘을 위해 아이템을 \(..
이 포스트는 국민대학교 소프트웨어학부 '빅데이터최신기술' 강의를 듣고 요약하는 포스트입니다. 원하시는 정보가 없을 수도 있습니다. 이 점 유의 바랍니다. 오류 지적은 매우 환영합니다! 문제 상황 (key, value)의 tuple로 이루어진 스트림이 있다고 합시다. 그러면, key 값들이 담긴 집합 S가 있을 때, 스트림 내의 임의의 튜플이 집합 S에 존재하는지 확인하려면 어떻게 해야 할까요? 가장 쉽게 생각할 수 있는 방법은 집합 S를 hash table에 모두 저장하는 방법입니다. 하지만 스트림으로 들어오는 튜플들의 수가 너무 많다면, 그 많은 튜플들을 하나씩 다 S에 탐색하는데 시간이 오래 걸릴 것입니다. 비트 배열을 사용한 필터링 비트 배열을 사용해 필터링을 하는 방법이 있습니다. 필터링을 해서 ..